LeetCode 刷题思路笔记
2026 为了找实习再一次捡起力扣,已经数不清是第几次重新开始刷题,过去的几次尝试都是坚持不了几天就放弃,导致每次都浅尝辄止,始终没能构建起属于自己的一套算法题思路和方法论。这种感觉就好比背单词每次都是 “abondon” “abondon” …,刷了忘忘了刷,久而久之这种看不到自己进步的挫败感就快把做算法题的兴趣和勇气都消耗殆尽。
因此今年这又一次的重启力扣,决心不能做过算过。我相信文字是对抗遗忘最好的武器。因此本次将尽量记录下做过的每道题的思路,希望在不断积累中慢慢找到做算法题的感觉,这非一日之功,重点在于日拱一卒,不断重复。
做算法题要有一种不卑不亢的心态,对于简单模版题,不必轻蔑;对于想不出来或调不出来的题,也不必自我否定。用理智对待这一过程:对于简单题是增加对模版的熟练度,对于难题更是学新东西的好机会。有时候做不出来直接学习题解,反而比自己死磕半天却“做过算过”更有价值。
本次记录从 2026 年 3 月始,下面的每一道题都是在这个时间节点之后提交过的题目(之前刷过的不算)。但要切记不可为了记录而记录,避免陷入形式主义。
链表
已刷:25 道
-
第一种:最简单的方式是用哈希表,把第一个链表结点的引用都放进去,逐一遍历第二个,表中存在的第一个就是相交节点。时间复杂度 O(m+n),空间复杂度是 O(n);
第二种:head1, head2 同时遍历两个链表,当走到空结点时换到另一个链表的头结点继续走,两个指针第一次相遇处就是相交的第一个结点(因为此时走的步数相同)。如果两个指针都为 None 说明不相交。时间复杂度 O(m+n),空间复杂度 O(1).
-
模版题。
-
第一种:把链表元素放进一个列表中,然后判断
nums == nums[::-1]。时间复杂度 O(n),空间复杂度 O(n);第二种:先找到中间结点,再反转后半链表,最后用两个分别指向两个头结点的指针逐一判断。时间复杂度 O(n),空间复杂度 O(1).
-
快慢指针,Floyd 判圈算法模版。
-
快慢指针,Floyd 判圈算法模版。
-
模版题。
-
遍历两个链表,处理好进位即可。只要两个链表和进位有一个还没完就得继续新建结点。
-
快慢指针。快指针先走 n 步,然后快慢指针一起走。详见模版。
-
方法一:递归,递归函数内处理两个结点的交换,后面的交由递归处理,递归返回后面处理完成后的新的头结点,再和前面连接。时间复杂度 O(n),空间复杂度 O(n);
方法二:迭代,没什么特别的,设置一个 dummy,
prev, cur = dummy, head,然后每次交换 cur 和 cur.next 两个结点,遍历一次即可完成。需要注意的是循环结束后可能有环,需要再额外处理一步。小心一点即可,可以画个图模拟一下。时间复杂度 O(n),空间复杂度 O(1). -
基本操作是反转链表,循环条件改成
for _ in range(k)。反转链表的函数需要返回两个结点,第一个是反转后的头结点,第二个是下一轮需要处理的头结点,即第 k+1 个结点,也就是新的头结点在原来的下一个结点。在反转之前要先判断剩下的长度是否大于等于 k,如果小于 k 则不反转,直接返回 head 和 None.方法一:递归,递归函数内处理 k 个结点的反转,后面的交给递归;结束条件是当前的链表长度小于 k;递归函数返回反转后的头结点,这样当“归”到第0层返回的正好是都处理完成后的新的头结点。时间复杂度 O(n),空间复杂度 O(n);
方法二:迭代,最简单的方式,新建一个 dummy,从头开始循环调用反转链表函数,把 cur 更新成反转链表函数的第二个返回值,直到第二个返回值为 None 说明处理完毕。时间复杂度 O(n),空间复杂度 O(1).
-
基本操作是找中间结点和合并两个升序链表。
仿照归并排序的分治:递归函数内先找中间结点,找完后要把中间结点前一个结点和中间结点断掉(为了后面合并的正确);之后分别递归处理左链表和右链表,这样就得到两个有序链表,再合并即可。结束条件是 head 为 None 或 head.next 为 None(只有一个结点)。时间复杂度:O(nlogn),空间复杂度 O(n).
这种做法是自顶向下使用递归进行归并排序,还可以不用递归,自底向上进行归并,空间复杂度为 O(1). 但尚未掌握,亟需掌握!
-
基本操作是合并两个升序链表。
仍然是归并排序的分治思想:先递归处理排序前 k // 2 个链表,再递归处理后面的,这样就得到了两个升序链表,进行合并就好了。唯一要转换一下思维的是递归函数的输入是一个二维列表,即链表的列表,但只返回一个排好序的单链表。时间复杂度:O(Llogm),其中 m 为 lists 的长度,L 为所有链表的长度之和;空间复杂度:O(logm).
同 148,依然可以自底向上进行归并,优化空间复杂度,亟需掌握。
-
普通的遍历。需要注意的是要删除所有重复数字的结点,一个不留,如果单纯判断
cur.val == cur.next.val会漏掉一个。所以用一个 record 变量记录每次的重复数字,只要前后结点值相同或当前结点值等于 record,就删除当前结点。这样做注意,需要在循环结束后处理最后一个结点也要删除的情况。 -
把链表连成环,然后只要找到需要断掉的位置即可。
-
找中间结点的前一个结点即可。
-
分别维护奇数结点和偶数结点的 prev,在一次遍历中同时处理好这一对即可。最后把两个链表连上。
-
找中间结点,反转后半链表,双指针分别从左右两端遍历找最大值。同 234. 回文链表 。
-
dummy 结点,遍历链表,删除结点。
-
遍历链表。值得注意的技巧是从最高位遍历到最低位去计算十进制数的方式。
-
反转链表的变形,需要注意的是反转后的新链表与前后结点的连接逻辑。
-
快慢指针模版。
-
经典面试题,两种写法,一种用 OrderedDict,另一种用双向链表手动实现。
-
第一种,用 collections.OrderedDict() 这一数据结构来维护 cache. OrderedDIct 就是一个有序的字典,并且可以 O(1) 的进行插入、删除、改变顺序等操作。提供了如下方法:
-
OrderedDict().move_to_end(key, last=True)表示将键为 key 的这一对移到最后,last=False就会移到最前面; -
OrderedDict().popitem(last=True)表示删除当前的最后一个键值对,last=False表示删除第一个;
其底层也是用一个双向链表+一个 key_to_node 的字典来维护实现的。
对这题来说,可以令排前面的是最近用到的,因此每次使用或添加一个元素就把它移到第一个,如果超过容量就删除最后一个,这样就实现了 LRU.
-
-
第二种是手动维护一个双向链表+字典来实现。字典存 key -> node 的映射。使用双向链表的原因是可以 O(1) 实现删除结点,单链表的话还要遍历找到前一个结点。其它都是基本逻辑,唯一值得注意的地方时双链表的维护逻辑,有一种很方便优雅的方式:
-
初始化一个 dummy 结点,其 prev 和 next 都指向自己;
-
插入结点(头插):
node.prev = dummy node.next = dummy.next dummy.next = node node.next.prev = node -
删除结点:
node.prev.next = node.next node.next.prev = node.prev
这样任何时候双向链表都能结成一个环,dummy.prev 指向尾结点,尾结点的 next 指向 dummy,即:
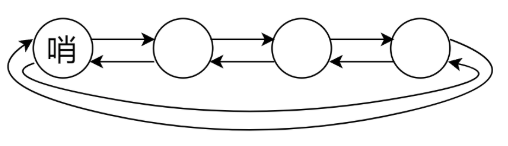
对于本题来说,将一个已经存在的结点移动到最前面的操作就可以分解为先删除,再头插。当然,这样做会导致环形链表,如果不想这样也可以用更常见的方式:用两个虚拟节点 head 和 tail 来维护。
-
-
-
模拟题。
- 方法一:遍历一次原链表,一遍遍历一遍新建结点,放在一个字典里。键是原结点,值是新结点(默认自定义类的对象是可哈希的)。之后再遍历原链表,利用字典连接每个结点的两个指针。空间复杂度 O(n);
- 方法二:遍历原链表,每遍历一个点就新建一个结点插在原结点后面。之后再次遍历链表,有这样的关系:
cur.next.random=cur.random.next。最后再用两个指针把两条链表分开即可。空间复杂度 O(1)。
-
第一眼觉得是类似于 partition 的做法放在链表上做,但实际写下来发现交换逻辑很容易乱套。更简单的做法是将其分割成两个链表,分别串联小于 x 和大于等于 x 的结点,最后再把两个链表串起来。新建一个 small_dummy 和 big_dummy,然后逻辑跟合并两个升序链表差不多。要注意的是遍历的时候最好先把结点原先的 next 指向空,避免形成环。
-
同 86。
二分
已刷:6 题
-
模版题。
-
模版题。
-
将 mid 转换为在矩阵中的行列下标。
-
一道好题。二分本质不是比大小,而是能够找到某种确定性的判断条件,每次减小搜索空间。本题只要能够写出 mid 和 target 分别在哪一段的几种情况即可。
-
33. 搜索旋转排序数组 的简单版。
-
-
第一种,对每一行或每一列进行一次二分。时间复杂度:O(mlogn) 或 O(nlogm),空间复杂度 O(1);
-
第二种是更巧妙的做法,但不能算是二分了。从矩阵的右上角开始,如果当前右上角的值小于 target,那所在行就可以排除了;如果大于 target,那所在列可以排除;如果等于 target 就找到。如果到最后行或列都减没了也没找到那就是不存在。
可以把这一二维矩阵看成以右上角为根的 BST,然后从根开始根据条件查找左右子树。
时间复杂度:O(m+n),空间复杂度:O(1).
-